
PythonでCSVファイルを利用する基本的な内容を解説します。
Pythonを使うと任意のデータを利用することも容易になります。
初歩的なことしか知らないと、
「Excelの方が便利だ~」
と思うだけで、
「プログラミングめんどくさい~」
としかなりません。
ネット上にあるオープンデータとして様々なCSVファイルが存在します。
これが活用できれば「できることの幅」が広がります。
Excelで処理しても良いですが、PythonでCSVを利用して簡便性を感じられるまでをご紹介します。
このブログでは、次の内容を紹介します。
- CSVファイルをネット上からダウンロードする
(もしくは既存のものを利用する) - PythonでCSVファイルを読み込む
- Pandasで簡単なデータ処理をしてみる
ネット上のCSVファイルをリンク指定で直接使用することも可能ですが、このブログでは、一度ダウンロードして、それを利用する方法にします。
ちなみに、Excelのファイルは、read_excel()で同様に処理できます。
※環境はGoogle Colaboratoryを利用します。
目次
CSVファイルについて
CSVとは、Comma Separated Valueの頭文字を取ったもので「カンマ区切り」という意味です。
「.csv」という拡張子です。
簡素なファイルなので、さまざまなデータを扱う際には便利なものです。
ネット上のCSVデータ
ネット上のオープンデータなどでもCSV形式で用意されていることが多いです。
ネット上にある自由に活用してよいデータは、基本的にリンクをクリックすればダウンロード可能です!
(クロムブックやiPadの場合は、リンクをクリックしてから右上のダウンロードボタンを押す必要があります。)
次のCSVファイルは、練習用に利用してもらって構いません。
※Excelファイルとして保存された場合は「CSV」に変更する必要があります。
ExcelでのCSVの取り扱い
CSVファイルは、Excelを起動して利用できますし、ExcelのデータをCSVにすることも可能です。
その方法は、ここでは書きませんが、ファイルを保存する際に「CSV」の形式で保存するとできます。
【注意】日本語を含むCSVファイル
CSVファイル内に日本語があると、ユニコードの指定などが必要になります。
このブログでは簡単のために英語のみCSVファイルを利用します。
つまり、今回のブログの内容においては、日本語を含むcsvファイルは利用できない、ということです。
ExcelのファイルをcsvにしてPythonで利用したい方は、(このブログの内容の範囲では)英語表記に直したものをご利用ください。
【準備】CSVファイルを利用するため
Pythonの環境が違うと、CSVファイルの利用方法も少しずつ異なります。
CSVファイルへのパスを通すための順番
CSVファイルをPythonで利用するためには、次の作業が必要です。
- CSVファイルをアップロードする
- CSVファイルのパスをコード内に記述する
JupyterNotebookなどを利用されている場合は楽ですが、Google Colaboratoryの場合は、準備が必要です。
GoogleColaboratoryでのCSVファイル利用
Google Colaboratoryをご利用の方は、次の2つの準備をしてください。
- CSVファイルをMyドライブ直下に移動する
(パスの理屈が分かる人は、この作業をする必要は一切ありません。) - ColaboratoryにGoogleドライブをマウントする
(このブログの【参考】の部分で行うことも可能です。)
この2つをしておいてください。
以下は、
Google Colaboratoryで、Googleドライブを接続(マウント)して、CSVファイルがMyドライブ直下に存在する状態
を想定して説明します。
次の画像を参考にしてください。
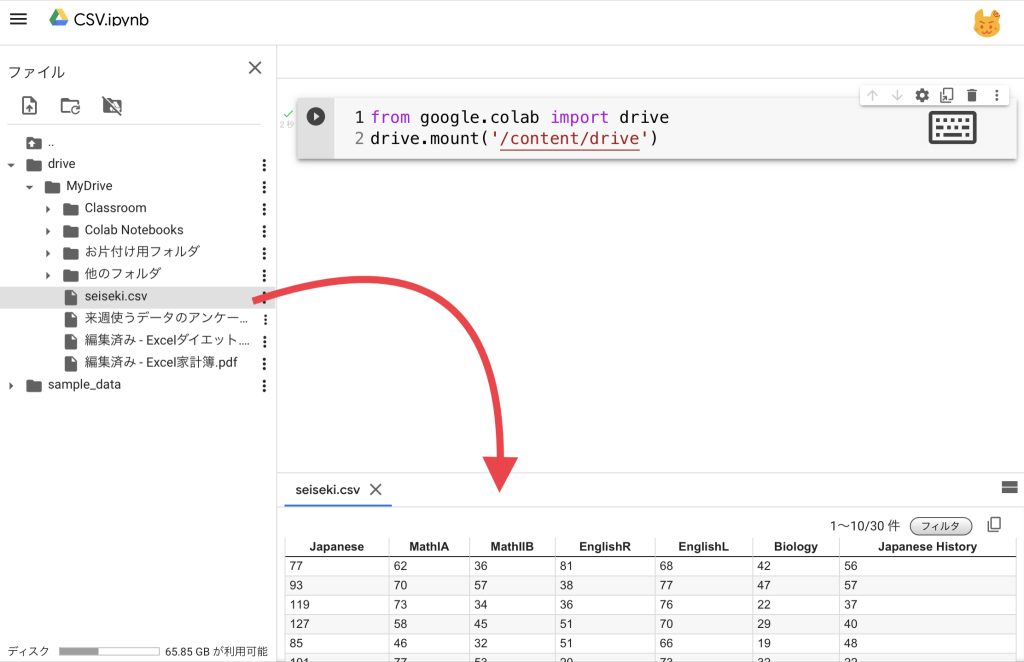
【CSV】PythonでのCSVの利用方法
PythonでPandasを利用したCSVファイルの利用方法を説明します。
Colaboraryの場合は、次の話を飛ばして、その次の話から書いてある通りに行っていただければできます。
今回は、上に用意した「seiseki.csv」を利用してみます!
次の説明がややこしい人で、Colaboratoryで実践している方は、次の見出しまでジャンプしてもOKです→ジャンプ
ファイルまでのパスの見つけ方
他の環境(Jupyter Notebookの場合、Colaboratoryも含む)の際は、次の魔法の呪文を整えて、CSVファイルの場所を確認してください。
import os
os.getcwd()この呪文を唱えると、パスが表示されます。
ここで表示されたフォルダを基準にコードを書きます。
一般的なパスの通し方
一般的な場合(例えば、JupyterNotebook)
○○/seieski.csvでCSVファイルが利用できると思います。
○○の部分に、上の呪文で表示されたチョンチョン ' 'の中身をコピペしてください。
(メイン画面で何も考えずにファイルをアップロードした場合です。。。)
GoogleColaboratoryの場合
Colaboratoryの場合は、上の呪文を行うと、'/content'と表示されます。
チョンチョン ' 'の中身が/content です。
今回は、MyDrive直下にファイルが存在するので、次のコードで「seiseki.csv」までのパスが通ります。
/content/drive/MyDrive/seiseki.csv「drive」が沢山でてきますが、その理由は、次の画像を参考にしてください。
準備が整いました、PythonでCSVファイルを処理する体験をしてみましょう。
Pandasライブラリを利用します。
【Pandas】CSVをPythonで確認する
PythonでCSVを扱うときには、Pandasを利用します。
Pandasのread_csv()を利用すれば、CSVファイルを読み込むことができます。
次のように入力してみましょう。
import pandas as pd
tokuten = pd.read_csv('/content/drive/MyDrive/seiseki.csv')実行して何も起こらなければバッチリです!
pandasで、CSVファイルを読み込み【read_csv】、tokutenという名前を付けました。
※他の環境で行っている場合は、/content/drive/MyDriveの部分を適切なパスに変更して下さいね。
このCSVファイルを表示させましょう。
tokuten.head()と入力して、実行すれば、tokutenというデータの表の上【head】から数えて5行分が表示されます。
次の画像になると思います。

tokuten.head(30)とすれば、データの表の上から30行分が表示されます。
【Pandas】CSVデータのヒストグラムをPythonで出す
得点のデータなので、ヒストグラムを出してみましょう。
細かいカスタマイズ/設定は省略して、とりあえずヒストグラムが表示できることを紹介します。
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10,10))
tokuten.hist(ax=ax)これを実行すると、ヒストグラムを一挙に出力することができます!
ぜひ、ご自身でやってみてください。

コードの意味を簡単に説明します。
一行目のimport matplotlib.pyplot as plt は、図を表示するためのライブラリmatplotlib.pyplotを読み込んでいます。
二行目にあるsubplotsが複数のヒストグラムを出力する指示になります。
※この部分は、たぬきねこの小部屋さんの「【Pandas】各列のヒストグラムを通る【Matplotlib, メモ】」のサイトを参考にしました。ありがとうございます。
tokuten.histで、データ【tokuten】のヒストグラム【hist】を出力する命令です。
tokuten.hist()だけで複数のヒストグラムが表示できるのですが、図が被ってしまうので、二行目の設定をしています。
【Pandas】CSVデータの基本統計量をPythonで出す
ヒストグラムをたくさん出して、図を描いた気分になれたので、基本統計量も出力しましょう。
今までの続きで、次のように記述しましょう。
tokuten.describe()今回のデータ【tokuten】の(基本統計量を)描写【describe】するという意味です。
これを実行すれば、いくつかの統計量を自動的に計算してくれます。

いいね👍
英語の意味は、
- count・・・データの個数/大きさ
- mean・・・平均値
- std・・・標準偏差
- min・・・最小値
- 25%・・・第一四分位数
- 50%・・・第二四分位数(中央値/median)
- 75%・・・第三四分位数
- max・・・最大値
ですね。
【まとめ】PandasでCSVデータ処理の体験
PythonのPandasでCSVデータを処理する手始めをじっくりと解説しました。
特に、Google Colaboratoryに準拠して書きましたが、ほかの環境でもできます。
この話を応用すれば、ネット上にある多くのデータを自分で活用できるようになります。
自分ができることの幅が圧倒的に広がりますね!
データファイルのパスを通すまでが難しいかもしれませんが、一度慣れれば何も難しくありません。
ぜひCSVファイルを活用してみましょう!
最後まで、ご覧いただき、ありがとうございます!

